Command Palette
Search for a command to run...
Search for a command to run...
웹서비스 운영에 있어서 중요한 것 중 하나는 “사용자가 활동하면서 발생한 오류”를 잡아내는 것이다.
특히, 첫걸음을 뗀 지 얼마 안된 서비스 일수록 중요하다. 사용자가 오류를 경험하면 불편할 수밖에 없다. 그리고 곧 해당 사용자는 떨어져나간다. 버그를 리포팅 하는 사용자는 100명중 1명 정도 밖에 되지 않는다.
그나마도 버그 리포트의 품질을 기대하기 힘들다. (사실 알려주는 것만 해도 상위 1%다.)
하나의 오류를 겪었다면, 같은 루틴을 밟는 더 많은 사용자가 있을 것이다. 그 사용자 모두 불편함을 느끼고 이탈 고객이 된다. 그뿐 아니라, 서비스에 대한 인상 또한 나빠져서 추후 “아 그거 별로던데” 말이 나올 수도 있다.
그래서 오류를 개발팀에 알려줄 수 있는 장치가 필요하다. 오류가 전혀 없는 코드는 이상속의 존재이다. 심지어는 Coq같은 도구를 쓰더라도 “로직 자체의 오류”는 여전히 남아있을 수 있다. 그러므로 오류가 발생했을때 단순히 사용자에게 알려주는게 아니라, 개발자에게 보고 되게끔 해야한다.
오류 처리는 개발 초반부터 만들어놔야 한다. 오류 처리를 후순위로 미룰 경우, 숨겨진 오류를 발견하지 못해서 개발 시간을 오히려 늘리는 문제가 생긴다. 발생한 오류를 바로 확인 가능하게 까지 한다면 “오류를 찾아 헤메는” 디버깅 시간 단축 효과도 기대할 수 있다.
아래의 사례는 실제 본인이 겪어본 버그 사례들이다. 일부는 실제 운영을 하면서, 일부는 서비스를 사용하면서 겪은 일들이다.
MSG가 소량 첨가됐을 수 있다.
장바구니에 물건을 다 넣고 주소와 정보를 다 입력했다. 그리고 결제를 하려고 하자 “결제 가능한 수단이 없다” 라는 메세지가 발생했다. 결제 수단으로 네이버페이를 선택했는데, 이쪽과 연동에 문제가 있었는지 결제가 안됐다.
새로 결제를 하려고 하자 결제 정보가 싹 다 날라가서 상품을 장바구니에 넣는것 부터 다시 시작했다. 일반 사용자였다면 진작에 나가 떨어졌을것이다.
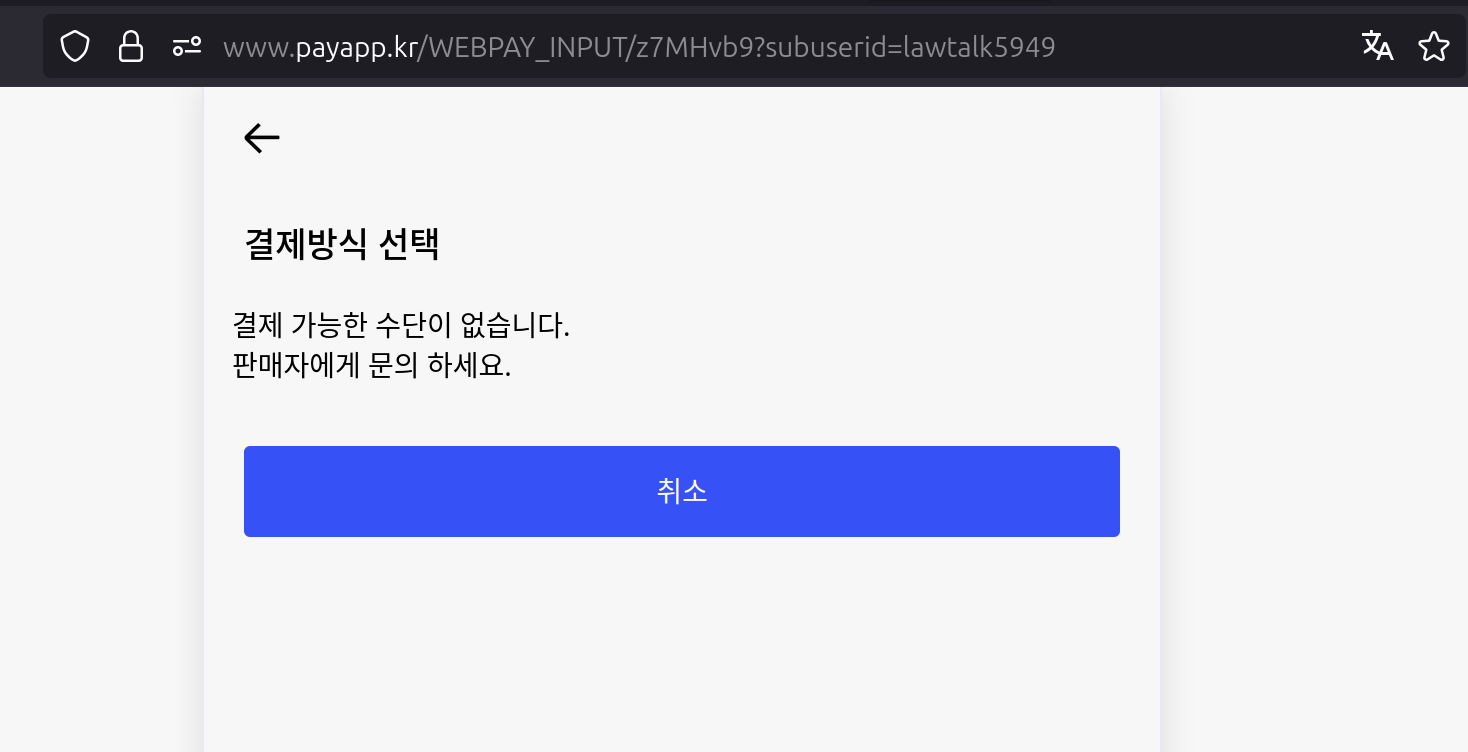
결제를 하려고 하자 결제 가능한 수단이 없다고 표시됐다. (세번이나 당했다..)
DB 테이블에 nullable인 컬럼을 추가했다. “어플리케이션 단에서 failback으로 null일 경우 다른 값 선택”을 하는 로직이 들어가 있었다. 문제는 아~주 오래전에 가입한 계정에서는 그 값 또한 null인 경우가 있었다.
그 때문에, 사이트 초창기에 회원가입을 했던 사용자는 로그인이 되지 않는 문제가 있었다.
비슷한 경우로, 사이트 초창기에는 “사용자 실명”을 수집하지 않았다가 이후 필수 수집을 한 경우가 있다. DB에는 이 값이 null로 설정된 사용자가 있었는데 application 단에서 null 체크를 안해서 그대로 문제가 발생한 경우가 있었다
어떤 사이트에서 특정 버튼의 링크가 깨져있던 일이 있었다. 비단 이 사이트 뿐 아니라 많은 사이트들에게서 이따금씩 발생한다.
내부적으로 공통 로직(거대 DB)이 있고, 이것을 스킨만 입혀서 분양해 주는 서비스가 있었다. 어느날 공통 로직을 업데이트 했더니 분양해준 사이트 중 일부에서 처리 불가 오류가 발생하기 시작했다.
이는 API를 제공하는 서비스에서도 종종 보인다. 시스템 업데이트를 하고나니 기존과 달리 API에서 원치 않는 데이터가 나올때가 있다.
일부 사용자가 “알 수 없는 이유로 회원가입이 되지 않는” 문제를 경험했다. 알고보니 저~~ 맨 뒤의 DB단에서 제약 조건이 근원이었다. 레포지토리 레이어, 서비스 레이어, 파사드 레이어를 건너오면서 디테일한 정보가 손실되어 단순히 “나중에 다시 시도해주세요” 와 같은 메세지가 발생했던 것이다.
이 경우 사용자도 난처하고 개발자도 난처하다. 알 수 없는 이유라고 하면… 뭐가 문제인지 감을 잡기 어렵다.
가장 먼저 분야를 나눠야 한다. 웹·앱 서비스를 기준으로 서버 단과 프론트로 나눌 수 있다. 그리고 각 분야에 에러를 리포팅 할 수 있는 도구를 붙여야 한다. 버그는 완전히 없앨 수 없다는것을 인정하는 대신, 버그가 발생했을때 알아챌 수 있는 방법을 가져야 한다는 말이다.

아래는 Rust에 있는 타입 시스템 중 일부이다.
Result<T, E> / Option<T>두개 모두 프로그램의 잠재적 문제를 구조적으로 풀어준다. 그 중 이번 쳅터에서 우리가 봐야하는 것은 Result<T, E>이다.
사실 Result도 합타입이 있어야지 완벽히 구현할 수 있다. 그래서 1번 또한 언급했다.
아마 코틀린을 해봤다면 비슷한 Result 타입을 봤을수도 있다. Result 타입은 Exception 과 데이터 또는 T 를 가질 수 있다. 그리고 Exception | T 를 개념상의 공간에 넣으므로서, 코드 흐름을 해치지 않으면서도 Exception을 우아하게 처리할 수 있다.
아래와 같이 여러 메서드들을 순차적으로 호출하는 메서드가 있다고하자.
@Transactional
public String createOrganization(String org_id, String name, long userId) {
User user = em.getReference(User.class, userId);
var org = orgService.createOrganization(org_id, name, user);
var key = apiKeyService.createApiKey(org, ApiKeySubjectType.ORG, userId, List.of(), "");
orgService.addMember(org, user, key, OrganizationMemberRole.OWNER);
return key.getKey();
}
이들만 보면 첫번째는 User, 두번째는 Organization, 세번째는 ApiKey 가 리턴될 것이라는것을 예측할 수 있다. orgService.addMember() 또한 적절한 타입을 리턴할 것이라고 기대할 수 있다.
하지만 실제로는 이것을 보장받을 수 없다. User가 null 일수도, org가 null일수도, key가 null일수도 있다. 현실적으로 모든 줄에 f (~~~ == null)체크를 하는것도 어렵다. 그나마 상기 언급할 대로 Kotlin에서는 ?가 있어서 null임을 알아차릴 수 있지만 Java에선 불가능하다.
각 메서드들이 Exception 을 던질 수도 있다. DB 트랜잭션과 외부 라이브러리와 연동이 되는 부분일 경우 듣도 보도 못한 오류가 발생할 수도 있다. 예를 들어, 외부 라이브러리를 사용하자 예상치도 못한 커널단의 TCP 오류, DNS 연결 오류등, 숨겨진 아랫단의 Exception이 올라올 수도 있다.
이 경우 개발자가 통으로 try-catch를 묶어야 한다. 하지만 그만큼 사용자에게 보여지는 오류의 정보는 줄어든다.
이것들은 개발자가 “개념”으로서 알고 있어야 한다. 즉, 코드 아래에서 숨어있으며 표면화 되지 않는다. Result<T, E>와 Option<T>를 사용하면 추상화 되어 있는 데이터를 실제 정규 데이터로서 사용하고 접근할 수 있다. 이것을 reification 이라고 한다.
문제를 덮어놓고 있으면 당장은 편하지만, 그 아래에 산적해 있는 문제를 알 수 없다.
T | null | Exception여기서 Rust의 Result<T, E>는 Exception 및 실제 데이터를 정규 데이터로서 옮길 수 있게 해준다. 또한, 타입 E 가 컴파일 타임에 제공되므로 개발자가 “어떤 오류가 올라올 것인지”를 충분히 파악할 수 있다. 정규 데이터로 옮겨지므로 try-catch 대신 if문을 사용할 수 있다.
물론 stack unwind를 통해 맨 위에서 통합적으로 Exception을 처리할 수 있다는 장점도 있지만, 오히려 코드 흐름을 방해하기도 한다.
그래서 필자는 왠만하면 Java에서도 Rust 스타일의 Result<T>를 도입하는것을 권장한다. 아래의 코드를 보자.
public @NonNull User login(String email, String password) throws LoginException {
var user_result = RustResult.wrap(() -> userService.findAccountByEmail(email));
if (user_result.isErr()) {
throw LoginException.UNKNOWN();
}
var user = user_result.getOrDefault(null);
if (user == null) {
throw LoginException.NO_ACCOUNT_FOUND();
}
if (this.passwordEncoder.matches(password, user.getPasswordHash())) {
return user;
}
throw LoginException.PASSWORD_INCORRECT();
}
필자는 코드에서 공통적으로 OkchunSuperException 를 만들어서 사용해서 제너릭을 쓰지 않았다. 만약 조금 더 범용적으로 사용하려면 E 도 제너릭으로 쓰자.
여기에는 STATIC_LOG.accept(e, sw.toString());가 있다. 그래서 혹시라도 Exception이 발생했다면 에러가 반드시 리포팅 된다는 것을 보장 받을 수 있다. 어딘가의 try-catch로 인해 숨겨진 미상의 Exception 마저도 관측할 수 있는 기반이 된다.
이 방식을 통해서 Java에서 발생할 수 있는 여러 숨겨진 오류를 처리할 수 있는 단단한 근간을 만들 수 있다.
오류에는 “재시도 할 수 있는 오류”와 “바로 멈춰야 하는 오류”가 있다. 예를 들어, 외부 API에 요청에 실패한 경우라면 “n초후 1회 재시도” 와 같은 재시도를 할 수 있다.
// AOP도 짜피 큰 틀에서는 동일하다.
void ExceptionReport(ProceedJoinPoint point){
for (int i = 0; i < 3; i++ {
try {
joinPoint.proceed();
break;
} catch (Exception e) {
report(e);
// 결국 try-catch 안에서 코드를 실행하고,
// 오류 발생시 report하는 똑같은 구조다.
}
}
}
1년전 만해도 spring-retry 같은게 있는지 모르고, 직접 AOP (pointcut 등)을 만들어서 직접 자동 retry, backoff 기능을 만들었었다.
특히, DB를 빡쎄게 쓰는 경우에는 이따금씩 (하루에 몇번 수준으로) 트랜잭션 실패가 뜰 때가 있다. 이때는 대게 재시도 하는것으로 문제를 해결할 수 있다. 그러므로, 간단한 재시도 로직을 사용해봄직 하다.
다만, 이로 인해서 아래의 문제가 발생할 수도 있다.
그렇기 때문에, 외부 API와 연동되는 경계 지점이라면 circuit breaker까지 적용해야 한다.
이제 우리는 Exception과 데이터를 평범한 로직으로 다룰 수 있게 됐다. 또한, 단일 Exception 지점을 얻었다. 이제 발생한 오류를 “외부로 알리는” 무언가가 필요하다.
하지만 무턱대고 Exception을 외부에 알릴 경우 상기 retry 로직에서 있었던 문제를 담습할 수 있다. [2번 – 메인쓰레드 문제의] 경우 아래의 코드를 떠올려 볼 수 있다:
// 일반적으로 메인 쓰레드에서 처리하는 로직
try {
SomethingException();
} catch (Exception e) {
try {
// 네트워크 오류시 여기서 15초의 timeout 대기가 발생
// 15초 동안 처리 쓰레드 자체가 blocking 돼 버림
ReportHttp(e);
} catch (Exception e) {}
// report 실패시 데이터가 유실됨
}
그래서 오류 보고 때문에 오히려 장애가 배수(*n) 또는 지수(^n)화 되는것을 반드시 방지해야 한다.
필자가 생각하기에 좋은 해결책 중 하나는 쓰레드 풀을 분리하는 것이다. 모든 요청은 메인 쓰레드에서 처리를 한다. 그러다가 “외부에 알려야 하는” 경계 지점이 온다면 외부 쓰레드에 작업을 넘기는 것이다.
외부 API 또는 서비스와 연계할 때도 방화벽처럼 쓰이는 방법이다. 다만, 일반적인 외부 서비스 호출에서는 “응답 결과”를 받아야 하기 때문에 쓰기 힘들다. 하지만 오류 보고에서는 Fire-and-Forget 방식을 쓸 수 있기에 알맞는 방법이 된다.
Rust, Go에서의 channel 같은 방식이다.
사실 “외부와의 경계 지점”이라면 가능한 적용해야 하는 패턴이기도 하다. 외부와의 연동은 언제 어떤 문제가 생길지 모른다. 그러므로 격벽을 놓는게 안전하다.
만약 메인 쓰레드에서 오류 리포팅을 한다면, “오류 리포팅”의 블로킹 때문에 HTTP 응답 쓰레드 전체가 멎을 수 있다. 예를 들어, 에러 리포팅 서버가 죽은 상황에서 “HTTP로 에러 리포팅”을 시도한다면 HTTP client에서 timeout (=15초 정도) 만큼 쓰레드 블록이 생겨서 오히려 정상 서비스까지 영항을 끼칠 수 있다.
또한, 동시에 사용하는 리소스의 수를 자연스레 제한할 수 있다. 내부 DB에 에러를 저장한다고 하자. 오류가 발생한 쓰레드에서 직접 처리한다면 DB Connection Pool에서 수십 ~ 수백개의 connection을 써버릴 수 도 있다. 하지만 오류 처리 전용 쓰레드를 만들고, 이것을 큐 마냥 처리한다면 실제 사용하는 DB Connection의 수는 쓰레드 수에 의해 제한된다.
가능하면 운영용 DB·네트워크와 오류 보고용 DB·네트워크가 분리되면 좋겠지만, 현실적으론 그렇지않다. 그러므로 운영측 장애시 오류 보고 서비스쪽도 접속 지연이 발생할 가능성을 고려해야 한다.
큐(채널)을 만들면 비동기적으로 에러를 리포팅 할 수 있다는 장점이 생긴다. 10초간 네트워크 단절이 있다고 하자. 기존의 메인 쓰레드에서 계속 처리한다면 1회 시도후 실패하면 넘어가는 방식으로 처리 했을 것이다. 하지만 큐에 들어갔다면 실제로 처리될 때 까지 큐에 남아있게 된다.
이를 통해 “최초의 장애(오류)”가 유실되지 않게 된다. 아래와 같은 일반적인 try-catch 에서는 report()가 실패하면 최초의 Exception이 손실된다.
단, Queue가 너무 길어지는 것을 경계해야 한다. 분당 1만개의 요청이 오는 서비스에서 장애가 발생했다면, 분당 1만개의 메세지가 쌓일 것이다. Queue가 정상적으로 소모되지 않고 있다면 메모리 폭주로 이어질 수 있다.
필자 생각에는 최초 n개의 메세지는 큐에 그대로 쌓고 이후는 셈플링 방식으로 큐에 쌓는것이 좋을 것 같다. 최초의 에러 지점과 에러 시점이 어딘지 아는것이 사후 대응에 큰 영향을 도움을 주기 때문이다.
그리고 일정 시간이 지나면 발생하는 오류가 대부분 동일해 진다. (같은 지점에서 오류가 발생하고 있을 것이다.)
Spring 밖으로 빠져나가려는 Exception은 @ControllerAdvice 에서 잡을 수 있다. 실질적으로 dispatchServlet 바로 다음에 존재하는 Exception Guard의 역할을 해 준다. 아래와 같이 사용할 수 있다.
@RestControllerAdvice
@RequiredArgsConstructor
public class GlobalExceptionHandler {
private final ExceptionLogger exceptionLogger;
@ExceptionHandler(OkchunSuperException.class)
public ResponseEntity<@NonNull GlobalResponse<GlobalErrorResponse>> handleException(
OkchunSuperException e, HttpServletRequest httpReq) {
exceptionLogger.log(e, e.getStackTrace(), httpReq);
return new ResponseEntity(new GlobalResponse(false,
new GlobalErrorResponse(e.getMessage(), e.getLocalizedMessage(), e.getParams())),
e.getStatus());
}
}
필자의 서비스는 영어를 기본으로 고려하고 있어서 e.getMessage()를 에러 코드로, e.getLocalizedMessage()를 번역된 기본 메세지로 사용했었다.
@ControllerAdvice 는 Exception에 관한 응답을 만들어주기도 한다. 위 코드와 같이 Exception에 HttpStatus 와 에러 코드등을 넣어서 클라이언트에게 공통된 응답을 만들어 낼 수도 있다.
필자는 어플리케이션 내부에서 “처리 가능한” 오류는 Rust 스타일의 Result로 처리를 했다. 그리고 처리를 더 이상 하지 못할 오류가 발생했다면 별도의 Exception 클래스를 만들어서 오류를 던졌다. 상속 계층 정리를 위해 OkchunSuperException 을 만들어서 사용했다. 이것을 @ControllerAdvice 로 받아서 공통된 GlobalResponse<T>로 외부에 표출했다.
public record GlobalResponse<T> (
boolean status,
T data
) {
public static<T> GlobalResponse<T> success(T data) {
return new GlobalResponse<>(true, data);
}
public static<T> GlobalResponse<T> fail(T data) {
return new GlobalResponse<>(false, data);
}
}
물론, 커스텀 Exception 대신 @ExceptionHandler(Exception.class) 를 사용해서 진짜 모든 Exception을 잡을 수 있다. API 규칙을 생성할 때 아래와 같은 응답 규칙을 만들었다면 @ControllerAdvice 를 통해 Spring에서 발생하는 모든 오류를 형태에 맞게 정리할 수 있다.
@ControllerAdvice 에 exceptionLogger.log(e, e.getStackTrace(), httpReq); 등의 코드로 에러를 로깅할 수도 있다. 어짜피 @ControllerAdvice 가 전역적인 오류 처리기이므로, 어플리케이션 코드에 통합하는것도 좋다.
Retry AOP등을 사용했을때 n회 재시도 모두 실패할 수도 있다. | 이것 또한 적절한 커스텀 Exception을 감싸서 n개의 오류를 통으로 보고하게 할 수 있다. 그러면 “DB의 부하가 높다”거나 “트랜잭션을 n회 시도 했으나 실패하는 경우가 꽤 있다” 등의 정보를 알게 될 수도 있다.
페이지 하나에서도 여러개의 오류가 발생할 수 있다. 극단적인 상황이지만 아래와 같은 경우가 있을 수 있다.
이 경우, 하나의 페이지에서 3개의 Exception이 발생할 수 있다. 특히 retry 로직을 넣는다면 발생할 가능성이 높아진다. 이것이 DB에 독립적으로 들어간다면 연속된 오류임을 알기 어렵다. 그렇기에, 오류를 로깅할 때는 Request ID를 부여해 주는것이 좋다.
Spring에는 HttpServletRequest 에 RequestId 가 있다. 평범한 Spring Boot라면 요청 순서에 따라 counter (integer)가 나온다. 이것만으로도 어느정도 구별이 된다. 여기서 사용자의 IP 또는 사용자의 Port를 조합하거나, 서버의 hostname을 넣으면 확실한 구분이 가능하다.
하지만, 조금 더 다듬고 싶다면 아래와 같이 필터에 request attribute 를 부여할 수도 있다. 이 경우, 뒤에서 작동하고 있을 Logger나 APM에서 requestAttribute 를 덤프하면서 request id 를 확인할 수 있다.
@Slf4j
@Component
@Order(Ordered.HIGHEST_PRECEDENCE)
public class RequestIdGenerator extends OncePerRequestFilter {
static final String SERVER_KEY;
static {
String SERVER_KEY_TMP;
try {
SERVER_KEY_TMP = InetAddress.getLocalHost().getHostName() + getServerKey();
} catch (UnknownHostException e) {
SERVER_KEY_TMP = getServerKey();
}
SERVER_KEY = SERVER_KEY_TMP;
}
private static String getServerKey() {
String SALTCHARS = "ABCDEFGHIJKLMNOPQRSTUVWXYZ1234567890";
StringBuilder salt = new StringBuilder();
Random rnd = new Random();
while (salt.length() < 6) { // length of the random string.
int index = (int) (rnd.nextFloat() * SALTCHARS.length());
salt.append(SALTCHARS.charAt(index));
}
return salt.toString();
}
@Override
protected void doFilterInternal(HttpServletRequest request, HttpServletResponse response,
FilterChain filterChain) throws ServletException, IOException {
request.setAttribute("REQUEST_TRACE_ID", SERVER_KEY + "_" + request.getRequestId());
filterChain.doFilter(request, response);
}
}
이 코드는 “서버의 Hostname”를 구하거나, 여의치 않으면 “랜덤한 6자리 글자”를 만든다. 덕분에 어느 서버에서 발생한 문제인지를 구별할 수 있다.
HttpServletRequest request 가 노출되어 있으므로, 클라이언트의 IP 등등을 사용할 수도 있다. 또한, 이것을 Http Response Header로 내보낸다면 브라우저에서 발생하는 문제들과도 결합해서 오류의 흐름을 볼 수 있다.
이 경우에는 사용자가 추측하기 어렵게 uuid 또는 random string을 쓰는것이 좋다.
스프링에서 발생하는 문제는 위의 방법들을 통해 어느정도 막을 수 있다. 하지만 프론트 Javascript나 Spring 밖에 있는 위치에서 발생한 오류(nginx, cdn) 등은 알기 어렵다.
실제 내용에 들어가기 앞서서, 오류를 보고할 때도 상기 만들었던 REQUEST_TRACE_ID 를 첨부한다면 서버-클라이언트의 문제를 매칭해 볼 수도 있다.
사이트를 개발하는 초반에도 꽤 도움이 된다.
예를들어, 서버에서 DB 호출에 실패해서, JS에서도 처리 불가로 오류가 발생했을 수 있다. 이 경우에 서버단의 오류 정보가 없다면 엄청나게 헤메게 될 것이다. “아니 이 값은 null일수가 없는데 왜 null이 들어와서 오류가 발생했지” 같이 말이다.
헤더에 이 값을 포함하고, 클라이언트의 오류 보고시에도 Trace ID를 첨부하는것이 좋다.
browser 기준, javascript에는 error 라는 이벤트 리스너가 있다. 이것을 활용하면 JS단에서 발생한 오류를 알아낼 수 있다.
addEventListener("error", (event) => {
/// 에러 처리
})
이때, 단순히 fetch로 요청을 보내는 대신 navigator.sendBeacon() 을 써보는 것도 좋다. 어짜피 fire-and-forget으로 에러 보고를 할 것이지 않은가? sendBeacon()을 쓴다면 브라우저가 적당한 시점에 적당히 데이터를 보내준다.
왠만한 경우라면 js 오류가 났을때 toast로 “에러 보고가 발생했습니다” 등의 메세지는 띄우지 않을 것이다
이렇게 만든 javascript는 가능한 모든 곳에 포함되도록 해야한다. 예를 들어, nginx에서는 error_page 라는 기능이 있는데, 여기서도 js를 로딩하게 해야한다. next, nuxt, nest, sveltekit 등에서는 public.html 따위의 HTML 파일이 있다. 여기 최상단에 배치하면 된다.
간간히 Next.js로 개발한 페이지에서 "a client-side exception has occurred" 가 뜨는 경우가 있다. 이런 경우에도 "자동으로 리포팅 하는 스크립트"를 심어 놓으므로서 문제가 있음을 알아챌 수 있는 방법을 만들어 놓는것이 좋다. (이미 whatap과 같은 상용 로거에서는 이런것이 있다.)
결국 핵심은, 오류를 어디선가 알 수 있는 방법을 만들어야 한다는 것이다. observation의 중요성을 끌고 와 보자면,, 수집된 데이터가 없으면 뭔가를 확인할 방법 자체가 없다. 이 경우 문제를 찾고 싶어도 찾을수가 없다.
그렇기에, 주기적인 점검은 못하더라도 에러를 모아모아서 추후 문제가 있을때 알 수 있게라도 하자.
다음글 미리보기: https://loghub.me/series/ESukmean/스프링으로-간단한-웹-프로젝트-돌려보기/5
로그인 후 댓글을 작성할 수 있습니다.